|

Nobel Prize Design in DNA
The Road to Discovery:
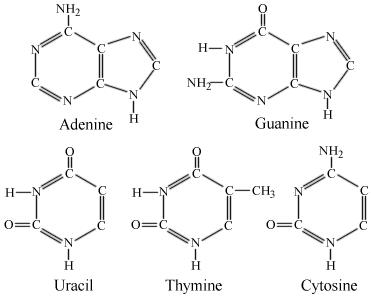
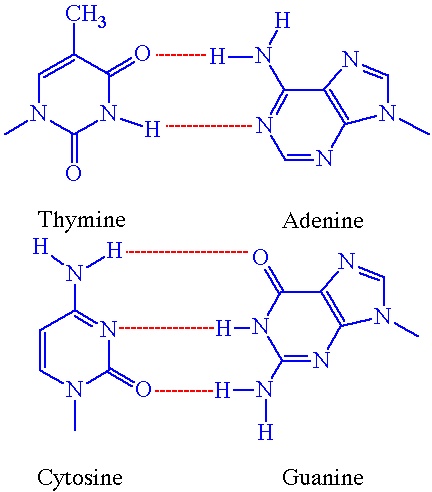
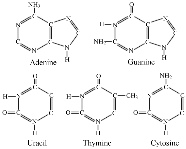 In [1902] Emil Fisher, won the Chemistry prize for the discovery of the chemistry of carbohydrates. He was the first to isolate the purines, the molecules which form one half of the DNA code Adenine and Guanine, the other half the closely related pyrimidines Thymine and Cytosine form the four bases of DNA. Adenine always joins with Thymine and Guanine with Cytosine to form the two DNA pairs. These two simple combinations form the code behind all living things. In RNA Thymine is usually (but not always) replaced by another pyrimidine, Uracil. Fisher also discovered the importance of the shape of enzymes through his study of sugar proteins. In [1902] Emil Fisher, won the Chemistry prize for the discovery of the chemistry of carbohydrates. He was the first to isolate the purines, the molecules which form one half of the DNA code Adenine and Guanine, the other half the closely related pyrimidines Thymine and Cytosine form the four bases of DNA. Adenine always joins with Thymine and Guanine with Cytosine to form the two DNA pairs. These two simple combinations form the code behind all living things. In RNA Thymine is usually (but not always) replaced by another pyrimidine, Uracil. Fisher also discovered the importance of the shape of enzymes through his study of sugar proteins.
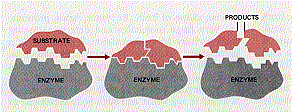 Eduard Buchner in [1907] was the first to demonstrate that enzymes could work outside the living organism by using the juices of yeast cells to achieve fermentation. Enzymes are biological catalysts which help speed up chemical reactions. They are used everywhere in organisms from helping digestion in our stomachs to destroying bacteria with our tears. Some enzymes, like fibrin, which controls blood clotting are made in an inactive state and made active when needed. Because enzymes are highly specific and often can bind to only a single molecule, some 10,000 enzymes are needed for our bodies to function, Eduard Buchner in [1907] was the first to demonstrate that enzymes could work outside the living organism by using the juices of yeast cells to achieve fermentation. Enzymes are biological catalysts which help speed up chemical reactions. They are used everywhere in organisms from helping digestion in our stomachs to destroying bacteria with our tears. Some enzymes, like fibrin, which controls blood clotting are made in an inactive state and made active when needed. Because enzymes are highly specific and often can bind to only a single molecule, some 10,000 enzymes are needed for our bodies to function,
| Blood Group |
Antigens |
Agglutinins |
Alleles |
| A |
A |
Anti-B |
AA or AO |
| B |
B |
Anti-A |
BB or BO |
| AB |
A and B |
Neither |
AB |
| O |
Neither |
Anti-A and anti-B |
OO |
The discovery of blood groups by Karl Landsteiner in 1900 was not given recognition until 1930. Its importance in medicine, allowing for safe blood transfusions to be done, was great. In genetics it was equally important since it was a dramatic confirmation of Mendel's laws of genetic inheritance. The discovery made by "the use of serological reagents ... led to an important general result in protein chemistry, namely to the knowledge that the proteins in individual and animal and plant species differ and are characteristic of each species." [1930a].
 Chromosomes - The 3 billion bases of the human genome are not all in one continuous strand of DNA. Rather, the human genome is divided into 23 separate pieces of DNA, called chromosomes. Chromosomes are strands of DNA bundled together by proteins. Humans have 22 numbered chromosomes (also called autosomes, and conveniently named 1 to 22) and the X and Y sex chromosomes. A typical cell has 2 copies of each of the numbered chromosomes, one from the mother and one from the father, and two sex chromosomes. Females have two X chromosomes, while males have an X and a Y. This results in a total of 46 chromosomes in each cell.[1933a]
Chromosomes - The 3 billion bases of the human genome are not all in one continuous strand of DNA. Rather, the human genome is divided into 23 separate pieces of DNA, called chromosomes. Chromosomes are strands of DNA bundled together by proteins. Humans have 22 numbered chromosomes (also called autosomes, and conveniently named 1 to 22) and the X and Y sex chromosomes. A typical cell has 2 copies of each of the numbered chromosomes, one from the mother and one from the father, and two sex chromosomes. Females have two X chromosomes, while males have an X and a Y. This results in a total of 46 chromosomes in each cell.[1933a]
|
The hereditary function of chromosomes was discovered by Thomas Morgan and recognized in [1933]. Chromosomes are long strands of DNA tightly wound in the nucleus of the cell, protected at the ends by telomeres. Their existence had been known since the 19th century. In 1903 Sutton was the first to pronounce them the source of hereditary traits. Together with the rediscovery of Mendel's work in genetics, the Darwinian theory of melding was overthrown. It would take decades of explanatory work by Wright, Fisher, Haldane, and Sewall-Wright to recast evolution to fit the new scientific findings.
Morgan's work, by discovering the crossing-over of genetic material that takes place during the production of the male and female sex cells finally showed how Mendel's theory worked. The parental and maternal chromosomes in each individual are duplicated. They are all joined together at which point crossing over of the parental and maternal genes can (but does not always) take place. The four chromosomes are afterwards split and each become part of a new sex cell with a single set of chromosomes in each. This crossing-over is the source of new genetic combinations in the progeny. In addition the individual chromosomes after separating are randomly sorted in the new cells. The entire process requires great precision and is fraught with the dangers of deletion, duplication, translocation, and inversion.
" It is estimated that from 10-20% of all human fertilized eggs contain chromosome abnormalities, and these are the most common cause of pregnancy failure." [1933b] .
The benefits of genetic recombination are great. They constantly recombine and thus re-unite the different genetic variations in a species. The process requires great care in properly sorting the chromosomes and in properly aligning the chromosomes during meiosis. The entire process with its various steps from the creation of a different mode of duplication of cells, through the sorting, the sexual conjugation and the sexual reunion producing again two sets of chromosomes in the progeny is clearly part of a single system which is useless without all the parts being present and working together with great exactitude. The development of such a system by haphazard stochastic methods is totally unimaginable.
In [1946] Herman J. Mueller won the prize for his work on radiation producing mutations. These mutations were random and not specific. Nevertheless by destroying various parts of the genetic structure at random, the purpose of the genetic material affected could be determined. Mutations were thus an early means of 'killing' genes in order to see by the absence of their function, what was the purpose of the gene. His work showed him that:
" we are already encumbered by countless undesirable mutations, from which no individual is immune. In this situation we can, however, draw the practical lesson, from the fact of the great majority of mutations being undesirable, that their further random production in ourselves should so far as possible be rigorously avoided. As we can infer with certainty from experiments on lower organisms that all high-energy radiation must produce such mutations [in] man, it becomes an obligation for radiologists - though one far too little observed as yet in most countries - to insist that the simple precautions are taken which are necessary for shielding the gonads."[1946a].
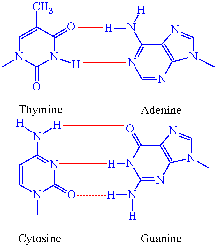 Linus Pauling was the kind of scientist we seldom see anymore, a "Renaisance" man of science making great contributions to physics, chemistry and biology. His [1954] Nobel Prize was in chemistry for his studies of forces holding together proteins. Proteins were far too complex to investigate by the methods current at the time so Pauling examined the structure of the amino acids. From the study of simpler structures and the theoretical relations of its elements he was able to give a description of the relationships in the DNA chain: Linus Pauling was the kind of scientist we seldom see anymore, a "Renaisance" man of science making great contributions to physics, chemistry and biology. His [1954] Nobel Prize was in chemistry for his studies of forces holding together proteins. Proteins were far too complex to investigate by the methods current at the time so Pauling examined the structure of the amino acids. From the study of simpler structures and the theoretical relations of its elements he was able to give a description of the relationships in the DNA chain:
"There is rotational freedom about the single bonds connecting the alpha carbon atom with the adjacent amide carbon and nitrogen atoms, but there are restrictions on the configurations of the polypeptide chain that can be achieved by rotations about these bonds: atoms of different parts of the chain must not approach one another so closely as to introduce large steric repulsion, and in general the N-H and O atoms of different amide groups must be so located relative to one another as to permit the formation of hydrogen bonds, with N-H··· O distance equal to 2.79 &- 0.10 Å and with the oxygen atom not far from the N-H axis. These requirements are stringent ones. Their application to a proposed hydrogen-bonded structure of a polypeptide chain cannot in general be made by the simple method of drawing a structural formula; instead, extensive numerical calculations must be carried out, or a model must be constructed."[1954a].
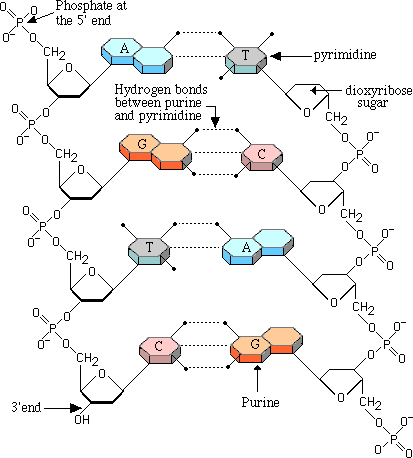
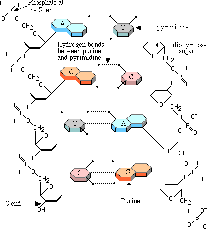 With the work of Sir Alexander Todd recognized in [1957] showing the role of DNA in genetics we have almost reached a complete description of the plan for DNA. Todd discovered that the DNA bases were held together 'as pendants in a chain" made up of sugar and phosphoric acid molecules. He found that RNA was unstable to alkali but DNA was not. Because DNA is so tightly packed in the chromosomes, observation was not able to show whether the DNA bases were arranged in a chain or branched out in many ways. Todd ascertained that they were arranged linearly due to the alkali instability which would have arisen if DNA branched on the phosphoric linkages. The arrangement thus established that DNA was able to code for an almost infinite variety of possibilities without any chemical interference as to their arrangement since each 'pendant' on the chain was joined in the same way to the chain as all others. Indeed, the arrangement is so malleable that the A-T and G-C base pairs can be (and indeed are) easily 'flipped' on the chain to show on each side of the chain the four different bases. With the work of Sir Alexander Todd recognized in [1957] showing the role of DNA in genetics we have almost reached a complete description of the plan for DNA. Todd discovered that the DNA bases were held together 'as pendants in a chain" made up of sugar and phosphoric acid molecules. He found that RNA was unstable to alkali but DNA was not. Because DNA is so tightly packed in the chromosomes, observation was not able to show whether the DNA bases were arranged in a chain or branched out in many ways. Todd ascertained that they were arranged linearly due to the alkali instability which would have arisen if DNA branched on the phosphoric linkages. The arrangement thus established that DNA was able to code for an almost infinite variety of possibilities without any chemical interference as to their arrangement since each 'pendant' on the chain was joined in the same way to the chain as all others. Indeed, the arrangement is so malleable that the A-T and G-C base pairs can be (and indeed are) easily 'flipped' on the chain to show on each side of the chain the four different bases.
The importance and significance of this arrangement cannot be exaggerated. Without violating the laws of chemistry, DNA nevertheless places itself beyond its influence. The material constraints on it are therefore non-existent and it is able to be arranged like letters in the alphabet, or like dots and dashes in Morse Code, like 0's and 1's in binary computers. This allows DNA to be arranged according to purpose, goal and function instead of according to physical necessities. It is thus perfectly suited for the design of a vast variety of complex organisms.
 Frederick Sanger was the first to break down and determine the exact amino acid sequence of a protein and received the Chemistry prize for it in [1958]. The insulin protein which he studied is an important hormone which was not only small (51 amino acids long) but also was clearly divided into two chains making the disassembly of it easier. Though small, the work yielded important discoveries (Note: residues is the name given to amino acids after bonding to others in a protein chain): Frederick Sanger was the first to break down and determine the exact amino acid sequence of a protein and received the Chemistry prize for it in [1958]. The insulin protein which he studied is an important hormone which was not only small (51 amino acids long) but also was clearly divided into two chains making the disassembly of it easier. Though small, the work yielded important discoveries (Note: residues is the name given to amino acids after bonding to others in a protein chain):
showed that proteins are definite chemical substances possessing a unique structure in which each position in the chain is occupied by one and only one amino acid residue. Examination of the sequences of the two chains reveals no evidence of periodicity of any kind nor does there seem to be any basic principle which determines the arrangement of the residues. They seem to be put together in a random order, but nevertheless a unique and most significant order, since on it must depend the important physiological action of the hormone. As yet little is known about the relationship of the physiological action of insulin to its chemical structure.[1958a] .
Beadle and Tatum won the [1958b] Prize by
demonstrating that the body substances are synthesized in the individual cell step by step in long chains of chemical reactions, and that genes control these processes by individually regulating definite steps in the synthesis chain. This regulation takes place through formation by the gene of special enzymes. If a gene is damaged, for example through irradiation-induced mutation, the chain is broken, the cell becomes defective - and may possibly be unable to survive. Even in the formation of comparatively simple substances the steps in the synthetic chain are many, and consequently the number of collaborating genes large. This explains simply why gene function appeared to be so impossibly complex.
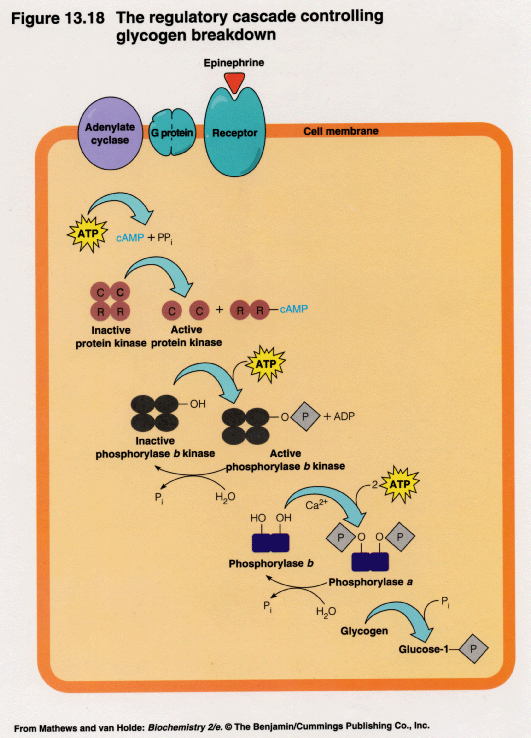
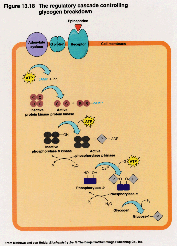 Interestingly while Beadle saw the problem for evolution presented by these chains - that they could not have arisen gradually since each step was necessary, he thought that an evolutionary solution was available. He proposed that the enzymes had replaced naturally occurring substances in the pathway, thus making gradual evolution of the chain possible. The problem with this is that there are numerous enzymes involved in these metabolic chains and analogues for hardly any of them exist in nature. The chains themselves constitute complex systems which must work perfectly and be carefully regulated. Glycogen catabolism is such a system. The body stores sugars in the form of glycogen and also turns it back into sugars by a different but also highly involved process (see figure) [1958c]. Interestingly while Beadle saw the problem for evolution presented by these chains - that they could not have arisen gradually since each step was necessary, he thought that an evolutionary solution was available. He proposed that the enzymes had replaced naturally occurring substances in the pathway, thus making gradual evolution of the chain possible. The problem with this is that there are numerous enzymes involved in these metabolic chains and analogues for hardly any of them exist in nature. The chains themselves constitute complex systems which must work perfectly and be carefully regulated. Glycogen catabolism is such a system. The body stores sugars in the form of glycogen and also turns it back into sugars by a different but also highly involved process (see figure) [1958c].
 The secret of DNA and RNA replication won the [1959]Nobel prize for Arthur Kornberg and Severo Ochoa. The processes are similar but not the same. The replication of DNA requires in bacteria three different DNA polimerases: Pol I is used to proofread and correct the copying process of Pol III which does the main job of replicating the DNA, Pol II's job has not yet been determined. In this work, they require the help of various enzymes: RNA primase copies a small section of DNA to get the work started (about 50 nucleotides), DNA Helicase splits the DNA double strand in two to enable replication, SSB's - single strand binding proteins keep the split strands from binding, DNA Ligase joins any splits left after Pol I does its joining and proofreading job in the newly formed chain. Pol III is the main agent of replication and has many jobs. It holds the two separated chains together while it replicates the DNA bases by adding the complement (A-T, G-C) to the base in the divided strand [1959a], [1959b]. Here we see again the beauty of DNA organization because the complement of each base is invariably the same, one can duplicate it by looking at only one side of the chain. This makes both duplication and error correction easy. Replication is so accurate that only one base in a billion gets copied incorrectly. The beauty of it all is amply shown in the award speech: The secret of DNA and RNA replication won the [1959]Nobel prize for Arthur Kornberg and Severo Ochoa. The processes are similar but not the same. The replication of DNA requires in bacteria three different DNA polimerases: Pol I is used to proofread and correct the copying process of Pol III which does the main job of replicating the DNA, Pol II's job has not yet been determined. In this work, they require the help of various enzymes: RNA primase copies a small section of DNA to get the work started (about 50 nucleotides), DNA Helicase splits the DNA double strand in two to enable replication, SSB's - single strand binding proteins keep the split strands from binding, DNA Ligase joins any splits left after Pol I does its joining and proofreading job in the newly formed chain. Pol III is the main agent of replication and has many jobs. It holds the two separated chains together while it replicates the DNA bases by adding the complement (A-T, G-C) to the base in the divided strand [1959a], [1959b]. Here we see again the beauty of DNA organization because the complement of each base is invariably the same, one can duplicate it by looking at only one side of the chain. This makes both duplication and error correction easy. Replication is so accurate that only one base in a billion gets copied incorrectly. The beauty of it all is amply shown in the award speech:
For proteins it has been proved, and for the nucleic acids it is highly probable, that the order of the different building blocks in the chains is by no means left to chance, but on the contrary is planned in detail for each kind of molecule and for each kind of living organism.[1959]
|
|